

Camunda BPM best practices

Introduction
BPM Platforms are engines in which BPMN Diagrams become a working code. There are many products implementing those concepts. Some of them are advertised as a low-code, ready-to-use by business without any programmers help. Some of them are just Java libraries, supporting Business Processes implementation at the software developer level. Many of them are struggling to gain both simplicity and the BPMN-driven code with ability to implement complex, specific requirements and tailor-made solutions. Among many, Camunda BPM stands out as a Platform which is an honest compromise between no-code simplicity and low-code capability. No matter which implementation model you will choose (find more about implementation models here: BPM Platforms: Standalone & Microservices implementations), the Business Analyst and the BPM Platforms Programmer can work together on the same Camunda project.
BPM Platforms ‘Holy Grail’: no-code concept
When do I need a programmer?
Now, you might probably wonder: “If no-code BPM Platforms exist – why do I need a programmer at all? There are many tools advertised as no-code concepts, where Business Process Experts are the ones to design and implement end-to-end processes”. The answer is simple: you don’t need a programmer, if your BPM Platform is used only for very simple process realization in only one business unit, without data integration. If you want to implement business processes on the organization level, which is business critical and require data integration, there is no no-code BPM platform which will fulfill your need.
In BlueSoft, we recommend Camunda BPM as the best trade-off between a simple, UI-driven business processes design (known from no-code platforms) and capacity to implement data integration and complex business rules with help of the IT engineer. The huge advantage of Camunda BPM is that the process design, done by the Business Expert, is a part of code which the IT engineer also works on.
Top Best Practices when implementing Camunda BPM processes
Now, when we know how to build teams working in Camunda BPM, let us focus on best practices and tools for Business Experts and IT Engineers when it comes to modelling processes.
When we think about the processes modelling, we have a lot of ways and tools to express ourselves. They are provided by a BPMN 2.0 standard: how a process should work and how it should communicate with other microservices or legacy systems. Unfortunately, when it comes to technical implementation, the standard approach is “less is more”. As programmers, we are used to sticking to this rule, but even then – this is not the indisputable truth.
The same goes for the modelling processes with Camunda Modeler. The common approach is to use parts only from the main path. However, as far as the understanding of the process from the perspective of other contributors to the project is concerned, we need to give them a little bit of help with an analysis part. In this case, lanes and external systems calls come in handy. We add those annotations without disturbing the way how the Camunda engine is processing the process .bpmn file.
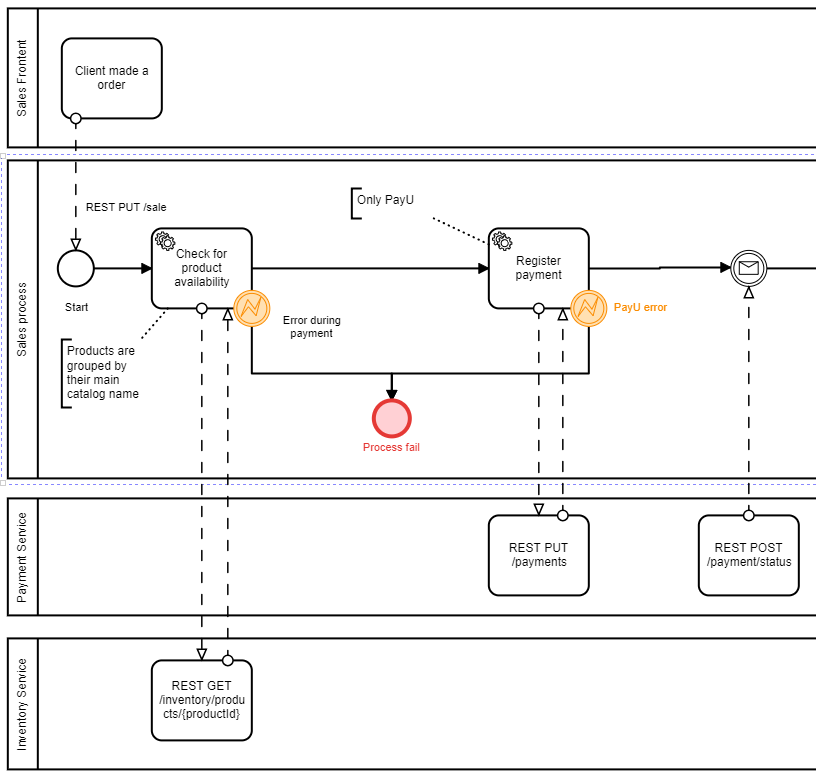
Now, let’s try to put ourselves in business analyst’s shoes. When trying to understand the process using only the main lane (the Sales process in our example diagram), we don’t have the slightest idea what exactly those two service tasks do. There can be a logic that calls internal database, or accesses a data from cache, or computes something from initial process data. But when all the parts are present, we clearly see that those steps call external systems. And we even know which particular REST request to external systems they use!
The company benefits from the above approach when it comes to an overall analysis of the process. This approach can be used as the first tool of expression when designing the high-level business process. The .bpmn file can be then sent to the development team to be used as an input file to start to work with.
Activities implementation principles
When it comes to readability of BPMN processes programming, principles come in handy. The most common anti-pattern is breaking the first rule of SOLID principles – “Single responsibility pattern”. This is one of the most important principle of today’s programming world. It states that a single class or package should be responsible for solving only one problem. It affects full spectrum of conceptual decisions from low-level class implementation to the high-level architecture design. As far as long term development and maintenance of a process is concerned, the step should be as simple as possible. It should be only responsible for calling an external system, serve end user a form or compute gathered data.
Implementing multiple external calls together or computing all data of the process in a single step are the most common mistakes. Even when the process was originally designed by the business analyst this way, it is development team’s responsibility to split this one business step into multiple technical steps, preserving the original business description.
The best line of defense is to stick with general flow – of course, this is only the basic visualization of the general idea:
- Step 1: Get data from external system’s call
- Step 2: Compute this data, transform it etc.
- Step 3: Serve the end user a form using the manual task from processed data. Important note – do not try to include a form of computing in this part! For dictionaries, etc., try to model your forms to use frontend-backend API.
- Step 4: Save data from the user form and transform it to the process model (if saving the form data is the only option, return from additional flow to Step 3)
- Repeat the generic idea
Remember to bring the configurability to the steps
Another important matter in the course of implementing processes in Camunda is a SOLID’s “Open-Closed” principle. Some steps will be very process-related and there is no reason to make the external configuration possible. But many of those steps, even when it comes to integration with other systems, can be reused – in different parts of the process or processes. To make this happen, we should use the element-templates (https://github.com/camunda/camunda-modeler/tree/develop/docs/element-templates). Modeler’s users can be provided with more flexibility in re-using process steps. Of course, it needs a little bit of configurability implemented for each of those activities. When it comes to accessing the common product data, sending e-mail or pushing to client’s mobile application, if you give more configurability to the step, the game might be worth the candle.
Exceptions handling and timeouts
Before the implementation takes place, we may take more time to analyze and design all exit points for all processes. Especially identification of all exceptions or error codes from the external systems’ call plays a vital role. We suggest making a dedicated matrix for each process. Last but not least, we need to design how the process should respond to those exceptions. There are two common approaches:
- The first one is to rollback all steps to the previous transaction point. Commonly, those would be the human manual task or the event handler. This kind of behavior is easy to implement but requires all data changes to external systems to be overridable in the next retry flow. And, of course, those changes cannot affect any business-related processes in corresponding systems).
- The second one is to use the default Camunda’s “retry and wait” mechanism. When Camunda tries to repeat the step (default 3 times) and then throw an exception waiting for an administrator’s action. This is a suitable approach when rolling back is exceptionally hard to implement or even impossible because of some business cases (for example, client has already paid for the product so there is no turning back). In this case, the external job or API calls must be considered to automate the retrying processes when the bug is fixed or system is back online. This commonly refers to the compensation flow.
Finally, we should consider the issue of processes timeout. In real industry cases, most processes should have a timer which ends them when there is no reaction from the client. Without it, the number of not finished processes can be ever-growing and extend to the number of hundreds of thousands. In most examples, the timer is only assigned to the human task. It is a valid and common approach, but what when we need to have the escalation at every step? Or the timer should be global? In this case, global handlers or escalation handlers should be modelled using BPMN processes, instead of purely programmatically approach, to provide more clarity for businesses analysts.
Avoid long processes
Avoiding long processes is an easy statement to say, but much harder to acquire when it comes to implementation. Sometimes we are forced to design processes, where human manual tasks can take months. This stands contrary to the previously mentioned microservice approach – short lived processes. The best way to prevent long-lived processes to occur is splitting processes into smaller ones, created only when the party made a decision / input valid data. But when you are forced to design and maintain those long-lived processes please remember those key problems which must be addressed before making any changes to the processes:
- Every single piece of data can be in any state and be part of the change. Sometimes it is impossible to list all variables in processes and create the upgrade matrix. The best approach when creating a new version of processes is to force moving all processes to the desired state with communicating this approach to businesses.
- Processes are versioned by default. But complex frontend forms and the code are not. Of course, you can use OSGi plugins systems (https://www.osgi.org/) and the couple versions of the code that had been maintained but in a real case scenario, it is a very rare approach as far as cost are considered. There are few frameworks who use all the features of OSGi (one of them is our open-source BPMN project – Aperte Worklow https://github.com/bluesoft-rnd/aperte-workflow-core) but even then it is very costly to maintain many versions of the same code for each existing process version.
- BPMN systems are not form-oriented portals. They force a particular data state to provide validation and flow. But because of that, they are very hard to maintain when this flow and data changes. The easiest approach is to force the completion of all processes before the production launch of a new version. In some cases, changes are related to additional steps and data that can be converted using a single script. But in those cases, when processes must maintain the current state, analysists must create “data-matrix” when data is presented as one dimension and the current state as the other one. And you should always analyze how the process would act when introducing a new version of the code working with historical state of data.
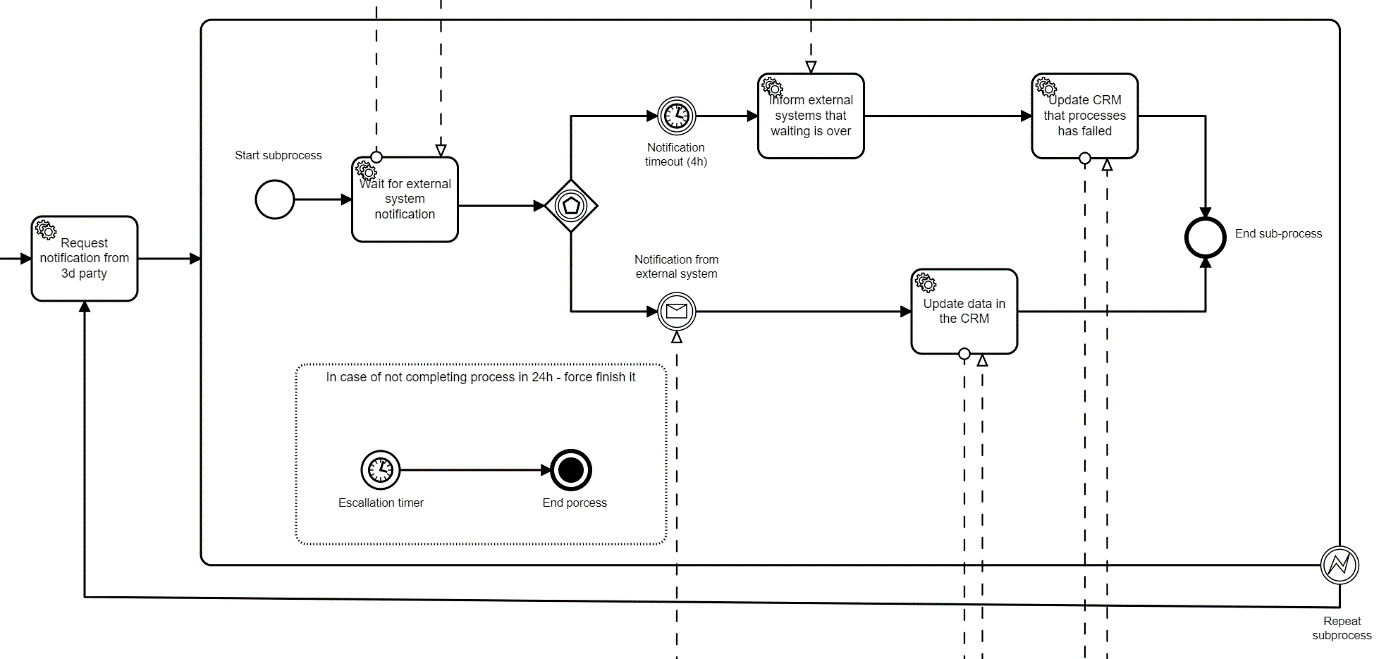
More of best practices.
The official documentation of Camunda is the great resource of best practices and we strongly advise everybody who takes part in designing processes or is a part of the development team to read it carefully – https://camunda.com/best-practices/using-our-best-practices/. In this particular article, we wanted to summarize our experience from many projects in which we took part to highlight the most common mistakes and how to avoid them. From our experience, the BPMN designing process is not an easy one and most knowledge is gathered while making mistakes which occur in the long run usage of those processes. We think that those highlighted bullet points are the key to design at least proper processes. Doing so is the great success for those who start their adventure with Camunda.
What Can We Do For Your Business?


