

Nasze podejście: Cyfryzacja i zarządzanie danymi w biznesie
Zaufanie do własnych danych stanie się łatwe dzięki niezrównanym wskazówkom od naszych ekspertów. Umożliwiamy wykonanie kolejnego kroku w procesie transformacji cyfrowej, pomagając przekształcić dane w informacje, a informacje w spostrzeżenia. Nasze usługi w zakresie przetwarzania i zarządzania danymi obejmują:
- Consulting – Nasi doświadczeni konsultanci pomogą Ci stworzyć solidne podstawy, na których zbudujesz architekturę danych od podstaw lub przeprowadzą audyty sprawdzające stan Twojej firmy w celu zaplanowania transformacji. Oczekuj światowej klasy porad, aby uzyskać projekt na wysokim poziomie.
- Dostawa – Pomagamy skonfigurować wymagane środowiska, wdrażamy rozwiązania E2E, obejmujące wszystkie warstwy przetwarzania danych, wprowadzamy Data Governance oraz dostarczamy odpowiedni zestaw narzędzi DevOps. Dzięki wiedzy i doświadczeniu na różnych rynkach i w różnych branżach, możemy zapewnić, że postępujemy zgodnie z najnowszymi i najlepszymi praktykami.
- Działanie – Powinieneś liczyć na płynne działanie bez zakłóceń. Zapewniamy przejęcia systemów, wsparcie 24/7 i usługi zarządzane, aby utrzymać opłacalność, stabilność i niezawodność Twojego rozwiązania w każdym możliwym aspekcie.
- Szkolenia – od inspirujących do zaawansowanych szkoleń, pomagamy szkolić pracowników i zwiększać świadomość danych w organizacji poprzez podstawy Data Governance takie jak Data Lineage, Data Ownership czy Data Catalogue.
Skontaktuj się z nami
Odkryj nowe możliwości dla swojego biznesu
Nasz proces: Oprogramowanie do zarządzania danymi
W BlueSoft wierzymy w ewolucję, a nie rewolucję. Wiemy, że przekształcenie się w firmę Data-Driven to podróż.

KROK 1
Określ wizję
KROK 2
Zacznij zarządzać
KROK 3
Wybierz architekturę i technologię
KROK 5
Analizuj, ucz się i badaj
KROK 4
Twórz potoki danych
W celu zakończenia tej podróży stworzyliśmy solidne ramy dla programu Transformacji Danych.
Zaczynamy od warsztatów Data Discovery, aby pomóc Ci sprecyzować Twoje potrzeby i wizję (faza 1), następnie zalecamy dostarczenie projektu PoC/MVP w ciągu 6-12 tygodni (faza 2), po czym następuje iteracyjny rozwój przy udziale interdyscyplinarnych zespołów Agile (faza 3).
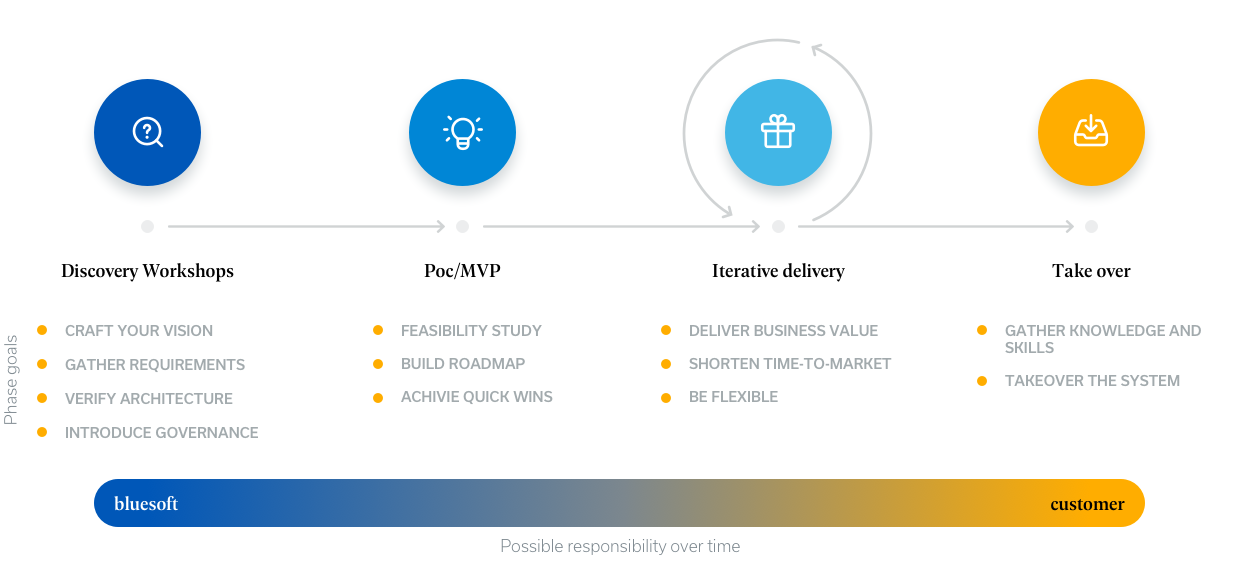
Ciągłe dodawanie wartości biznesowej w oparciu o dane jest kluczowym celem każdego działania.
Technologie, z których korzystamy
Opanowaliśmy ponad 200 technologii (takich jak Hadoop, Kafka, NiFi, Hive, Flink, Spark, HDFS, Oracle, MS SQL, AWS EMR, Azure HDInsight, Google Big Query, AWS Redshift, AWS Glue, Azure DataBrick i wiele innych), mamy know-how, aby przekształcić Twoje dane w informacje. Dzięki odpowiednim technologiom jesteśmy w stanie zbudować holistyczne platformy danych w ramach odpowiedniej architektury, która spełni Twoje potrzeby.





Poznaj naszych ekspertów ds. danych
Jest to nasz w pełni wykwalifikowany zespół z praktycznym doświadczeniem w budowaniu platform danych i ich przetwarzaniu.

Piotr Ziętek
Head of Data Services

Maciej Kossakowski
Senior Solution Architect

Łukasz Karwot
Senior Big Data Architect
Budujemy długotrwałe relacje z naszymi klientami
Z dumą pracujemy dla:


Historie naszych sukcesów
Nasze projekty
Z powodzeniem dostarczyliśmy wiele platform danych i rozwiązań do ich przetwarzania przedsiębiorstwom z różnych branż. Od budowania hurtowni danych i jezior danych po rozwiązania oparte na chmurze lub hybrydowe, od tworzenia dashboardów po konfigurowanie analityki predykcyjnej i uczenie maszynowe. Aby dowiedzieć się więcej, zapoznaj się z którymś z przedstawionych tu przypadków.


API Management & Governance dla Raiffeisen Bank International AG

Rozwiązanie kredytowe dla konsumentów Raiffeisen Bank Croatia

Raiffeisen Bank Hrvatska przekształca swoją architekturę danych w kierunku podejścia Data-Driven

Wdrożenie inteligentnego zarządzania API w ING Bank Śląski z Agama API
Wychodząc naprzeciw powyższym założeniom, w ING Banku Śląskim wdrożono rozwiązanie, wykorzystujące produkt do zarządzania API firmy BlueSoft - Agama API.
Rekomendacje
Co mówią o nas nasi klienci?
Mariusz Szydło
Dyrektor IT w KI One S.A.Dzięki pracy BlueSoft znacznie usprawniliśmy rozwiązania informatyczne wdrożone w naszej firmie. To, co wcześniej było wyzwaniem, teraz stało się bezproblemowym zadaniem, którego efekty są wyraźnie widoczne. Wykorzystanie komponentów chmury sprawiło, że cały projekt został zrealizowany szybko i niezawodnie. Praca ze specjalistami BlueSoft była dla mnie prawdziwą przyjemnością.
Adam Schulz
Dział Rozwoju Biznesu w Volkswagen Financial ServicesInicjatywa RPA w Banku przerosła nasze najśmielsze oczekiwania. Udało nam się zoptymalizować procesy biznesowe, które były wąskim gardłem naszej organizacji. Wiedza, zaangażowanie i partnerskie podejście BlueSoft pozwoliło nam stworzyć własne Automation Competence Excellence Center i wdrożyć nowe roboty szybciej niż początkowo planowaliśmy.
Marcin Anisko
Kierownik IT w Volkswagen Financial ServicesZe względu na wprowadzenie Salesforce firma VWFS potrzebowała warstwy integracyjnej z niezawodnymi, wysoce dostępnymi usługami RESTful i interfejsami API hostowanymi w skalowalnym środowisku chmury. Wybór rozwiązania MuleSoft był naturalną częścią wprowadzanego przez nas w Banku stosu technologicznego Salesforce. Szukaliśmy partnera, który pomoże nam skonfigurować Zarządzanie Integracją i ESB & API Gateway Platform oraz dostarczać pierwsze usługi. Wybraliśmy BlueSoft jako partnera z dużym doświadczeniem w zakresie najlepszych praktyk MuleSoft i SOA.
Adam Suchocki
Architekt korporacyjny, Architekt rozwiązań chmurowych w British CouncilZespół profesjonalistów. To oni opracowali złożoną strategię wdrażania chmury dla całej naszej organizacji. Dwieście centrów danych, 80 aplikacji biznesowych i ponad tysiąc serwerów spełniły wszystkie nasze potrzeby. W efekcie byliśmy w stanie zbudować spójne strategie migracji dla naszych obecnych i przyszłych projektów. Współpraca z BlueSoft była dla nas przyjemnością.
Mikołaj Siedlarek
Główny Architekt Korporacyjny w Inter CarsWejście w nowy obszar IT jakim jest Big Data, jest zawsze wyzwaniem dla firmy. Dlatego tak ważne jest, aby zrobić to z odpowiednim Partnerem IT. BlueSoft wspiera nas od pierwszego dnia – od wspólnego budowania holistycznej wizji rozwiązania po wsparcie sprawnego dostarczania i utrzymania jako jeden zespół.
Enkelejd Zotaj
Dyrektor Wykonawczy ds. IT, Raiffeisen Bank CroatiaPlatforma StarBoost dostarczona przez BlueSoft stała się elementem, umożliwiającym przeprowadzenie cyfrowej transformacji. Umożliwiło to Bankowi zastosowanie nowoczesnych wzorców architektonicznych oraz uzyskanie optymalizacji kosztów działalności poprzez zastosowanie technologii open source. Projekt dostarczenia platformy trwał 3 miesiące i zaraz po jego zakończeniu rozpoczął się proces tworzenia i dostarczania usług biznesowych napisanych w architekturze mikroserwisów. Biorąc pod uwagę jakość dostarczanych rozwiązań, doświadczenie, wiedzę oraz sposób dzielenia się nią z naszymi pracownikami, uznajemy BlueSoft za kluczowego partnera w procesie cyfrowej transformacji.

Łukasz Mosiej
Dyrektor Departamentu klientów korporacyjnych w BlueSoftWarto podkreślić wyjątkowe zaangażowanie pracowników BlueSoft, którzy pracowali nad systemem Financial Shield również w okresie świątecznym, w umożliwienie innym przedsiębiorcom przetrwania tego trudnego okresu.
David Vazquez
Starszy Dyrektor ds. Technologii Biznesowych w ZoetisJakość usług BlueSoft, elastyczność i doświadczenie w dostarczaniu wartościowych rozwiązań dużym międzynarodowym klientom przyczyniły się do jej rosnącego sukcesu. (…)
Biorąc pod uwagę sukces, jaki osiągnąłem z BlueSoft na przestrzeni lat, gorąco zachęcam starszych liderów IT do rozważenia jej jako strategicznego partnera.
Maciej Barczuk
Ekspert ds. optymalizacji procesów w Raiffeisen Bank Polska SABudowanie rozwiązań multi-channel stało się kluczowym wyzwaniem dla sektora bankowego, który przechodzi cyfrową transformację. BlueSoft, nasz zaufany partner IT, wspierała Raiffeisen Polbank w tworzeniu innowacyjnego systemu płatności mobilnych przez cały cykl rozwoju. Co więcej, najlepsze praktyki Agile, stosowane przez BlueSoft, pomogły nam w procesie transformacji i doskonalenia naszego środowiska pracy.
Magdalena Gniadek
Kierownik Działu Programów Lojalnościowych Polskich Linii Lotniczych LOTDzięki wprowadzonym zmianom LOT oferuje obecnie program z przejrzystymi warunkami i funkcjonalnym narzędziem do zarządzania nim.
Rafał Nawłoka
Prezes Zarządu DPD PolskaWprowadzenie terminali płatniczych, wraz z siecią nadawczo-odbiorczą Pickup, to najważniejszy projekt prokliencki realizowany przez DPD Polska w tym roku.
Tomasz Stańczyk
Kierownik Zespołu Projektowania Usług IT w BudimexWsparcie konsultantów BlueSoft w zapewnieniu stabilności i skalowalności platformy integracyjnej było niezbędne w kontekście budowania zaufania do szyny integracyjnej jako centralnego elementu architektury IT.
Hallvar Dehli
CEO i założyciel w PolarbulkBlueSoft wspierał nas w tworzeniu rozwiązania, które zwiększa wydajność i może być oferowane klientom w modelu SaaS. Była to nasza pierwsza inicjatywa informatyczna o szerszym zakresie, która doprowadziła do strategicznego partnerstwa i współpracy z BlueSoft.
Grzegorz Patynek
Współzałożyciel, Dyrektor Zarządzający w CO3Informatyka jest siłą napędową naszej wartości biznesowej, dlatego potrzebujemy rozwiązania informatycznego i Partnera, który pomoże nam dostarczać tę wartość naszym Klientom. BlueSoft zapewnia jedno i drugie.
Piotr Tabor
Kierownik ds. zapewnienia jakości w Trans.euWysoka dostępność IT i skalowalność są kluczowe dla naszego biznesu. Platforma dostarczona przez BlueSoft pozwala nam sprostać najwyższym oczekiwaniom rynku, a jakość świadczonych przez nią usług wskazują na to, że BlueSoft jest wiarygodnym partnerem IT.
Tomasz Wróbel
Dyrektor Departamentu Aplikacji Centralnych w ING Bank ŚląskiBlueSoft, jako jeden ze strategicznych dostawców ING Banku Śląskiego, zbudował dla nas innowacyjny system, wspierający komunikację operacyjną i marketingową multi-channel z naszymi klientami. Przejmując pełną odpowiedzialność za projekt, BlueSoft wykazała się rzetelnością i doskonałą jakością dostarczanych produktów na każdym etapie projektu.
Karol Wasiowski
Główny Specjalista ds. Rozwoju Aplikacji Biznesowych w Portal SprawiedliwiElastyczność i zorientowany na jakość zespół specjalistów BlueSoft pozwolił nam na uruchomienie innowacyjnego portalu Polscy Sprawiedliwi. Kompetencje i dobre relacje z BlueSoft z pewnością doprowadzą nas do pomyślnej realizacji kolejnego etapu projektu.
Nilo Paredes
Globalny lider marketingu cyfrowego, Business Technology w ZoetisKiedy Zoetis wystartował w 2013 roku, postanowiliśmy zmienić nasze globalne operacje cyfrowe.
BlueSoft był nie tylko integralną częścią tej cyfrowej transformacji, ale także pomógł nam poprawić nasze wyniki zarówno w zakresie technologii, jak i dostarczania. BlueSoft stała się zaufanym partnerem w ekosystemie Zoetis.
Maciej Barczuk
Ekspert ds. Optymalizacji Procesów, Raiffeisen Bank Polska SABudowanie rozwiązań multi-channel stało się kluczowym wyzwaniem dla sektora bankowego, który przechodzi cyfrową transformację. BlueSoft, nasz zaufany partner IT, wspierała Raiffeisen Polbank w tworzeniu innowacyjnego systemu płatności mobilnych przez cały cykl rozwoju. Co więcej, najlepsze praktyki Agile, stosowane przez BlueSoft, pomogły nam w procesie transformacji i doskonalenia naszego środowiska pracy.
Ariel Zgórski
Kierownik Programu w Architekturze TouchPoint Kontekst Klienta i Powiadomienia w ING Bank ŚląskiWsparcie BlueSoft pomogło bankowi w zbudowaniu wydajnego i stabilnego rozwiązania, co przełożyło się na lepszą obsługę klientów w banku.
FAQ
Kto powinien udzielić odpowiedzi na pytania z DDMM?
Idealnie, jeśli w ankiecie biorą udział 2-3 osoby: przedstawiciele managementu jak i osoby techniczne. Pożądane role to
- Chief Data Officer
- Architekt danych
- Product Owner platformy danych
- Liderzy zespołów
- Analitycznych
- Data science
- Raportowych
Ogólnie wskazana jest reprezentacja przekrojowa, żeby zobaczyć szerszy horyzont (często różne role widzą te same zagadnienia inaczej)
Ile trwa przeprowadzenie warsztatów discovery i jaka jest zalecana liczba uczestników?
W dużej mierze czas trwania i liczba warsztatów zależy od konkretnego przypadku i zakresu tematów do poruszenia. Zwykle przeprowadzamy nie mniej, niż 4 warsztaty po min 4h
- Otwierający
- Min. 2 sesje tematyczne (brainstorming)
- Podsumowanie
Ile czasu trwa wdrożenie waszego rozwiązania Data Catalog?
Odpalenie aplikacji w postaci out-of-the-box czyli takiej w jakiej jest obecnie oferowane (predefiniowany zestaw konektorów i funkcjonalności)
- Cloud (AWS/GCP/Azure) – 2 sprinty
- On-prem – 3 sprinty
Po wdrożeniu zestawu „startowego” wymagana jest integracja z systemami i wypełnienie metadanymi z tych systemów – czas trwania tego etapu w dużej mierze zależne od ich liczby i czasu potrzebnego na uzyskanie odpowiednich dostępów (np. do baz danych)
W przypadku zapotrzebowania na nowe funkcjonalności (zmiany w UI, nowe konektory (crawlery / hooki), nowe moduły itd.) -> Najpierw wdrażamy istniejące rozwiązanie a potem zgodnie z metodyką agile implementujemy i wdrażamy wymagane zmiany.
W czym Glossy jest lepszy od rozwiązań dostępnych na rynku?
Generalnie narzędzia typu data catalog możemy podzielić na 2 kategorie:
- Narzędzie natywne – takie jak Pureview (Azure), Unity (Databricks), Tablueau Data Catalog są natywnymi narzędziami dla danej platformy / technologii. Jest to ich duża zaleta, ale również wada. Zaletą jest doskonała integracja z danym środowiskiem, ale z tym co się dzieje “na zewnątrz” narzędzia te mają już większy problem. Zwłaszcza, jeśli mówimy o rozbudowanych przepływach danych, przechodzących przez kilka technologii (np. HDFS -> Sqoop -> HDFS -> Spark -> Hive -> Azure)
- Narzędzia uniwerslane – rozwiązania takie jak Alation, Data Hub. Te narzędzia nie są „przypięte” do jednej konkretnej technologii, ale również są gotowymi, zamkniętymi produktami. Możliwość dostosowania / zmodyfikowania ich do własnych wymagań jest bardzo ograniczona
Glossy zaliczamy do drugiej kategorii – narzędzi uniwersalnych. Ze względu jednak na nasze podejście “szyte na miarę” zakładamy, że każdy klient może mieć własne konkretne potrzeby i wymagania. W efekcie u każdego klienta Glossy może wyglądać nieco inaczej lub mieć trochę inne funkcje.
Jakie inne narzędzia niż data catalog mogą wspierać wdrożenie data governance?
- Słownik pojęć biznesowych (może być częścią DC, ale może też być oddzielnym rozwiązaniem)
- Master Data Management – centralne zarządzanie golden rekordem, czyli jedynym źródłem prawdy o pojęciach biznesowych
- Budowa frameworka data quality
- Wszelkiego typu narzędzia umożliwiające profilowanie i tagowanie danych
- Cały obszar związany z dostępem do danych i jego monitorowaniem
A co w przypadku, kiedy moja firma ma już inny data catalog?
Nie jest naszym zamiarem sprzedaż na siłę naszego rozwiązania i w pełni rozumiemy fakt, że firma może mieć już wybrane inne narzędzie tego typu. Przede wszystkim najpierw skupiamy się na jak najlepszym wykorzystaniu już istniejących i wykorzystywanych przez organizację narzędzi. Wszystko tak naprawdę zależy od wyniku warsztatów i przygotowanej wizji rozwiązania: jeśli Glossy wpisuje się w tę wizję, to bardzo na to cieszy. Ale jeśli nie, to jak najbardziej chcemy i możemy pracować z narzędziami, które zostały wybrane przez klienta
Jaki macie sposób na pokonanie oporu przed wdrożeniem Data Governance?
Naszą „receptą” jest właśnie podejście oddolne. Taką inicjatywę można zapoczątkować na średnim / niższym poziomie zarządczym, np. na poziomie konkretnego obszaru / domeny biznesowej. Przede wszystkim chodzi o to, żeby trafić z inicjatywą do ludzi, którzy na co dzień pracują z danymi, rozumieją ich wagę i potrzebę zarządzania nimi. Taka mniejsza, punktowa inicjatywa jest łatwiejsza i szybsza w realizacji. Wieści o sukcesach szybko się roznoszą i w niedługim czasie inne Działy i komórki firmy same będą skorzystać. To mieliśmy na myśli mówiąc o tym, że Start Small może być katalizatorem zmian.
Jak może wyglądać proces wybierania ownera i stewarta danych oraz ich aktualizacji w przypadku zmian organizacyjnych? czy to jest wykonywalne w rzeczywistości?
Proces wyboru data ownera i data stewarda jest ściśle związany z procesem zdefiniowania ról procesowych i zakresu ich uprawnien. Mimo pozornie podobnego zakresu odpowiedzialności dla obu z powyższych ról, mają one również kilka kluczowych różnic:
- Data Owner – jest osobą odpowiedzialną za klasyfikację, wiedzę biznesową jak i określenie miar jakościowych dla danych z danego obszaru
- Data Steward – jest osobą bardziej techniczną, która wspiera data ownera w zaadresowaniu i realizacji zadań związanych z Data Governance
Wskazane jest więc, aby data owner posiadał większą wiedzę biznesową, natomiast data steward bardziej techniczną.
Oczywiście istnieje możliwość wymiany osób dla obu tych ról, lecz należy zwrócić uwagę, że zakres wiedzy i wymaganych umiejętności dla obu tych ról jest różny.
Jak wdrożyć data gov w małych organizacjach, w których nie jesteśmy w stanie wydzielić osobnych struktur - żeby to żyło po zakończeniu projektu?
Tak jak podkreślaliśmy podczas webinaru, Data Governance to 3 elementy: ludzie, procesy i technologie. Zdefiniowanie ról w procesach, określenie właścicielstwa danych itd. jest ważne, ale nie oznacza to, że w tym celu trzeba wydzielać oddzielne struktury w organizacji, tworzyć nowe stanowiska itd. W przypadku mniejszych firm jak najbardziej możliwe jest przypisanie ról procesowych w ramach istniejących struktur. Od struktur i stanowisk dużo ważniejsze jest jednak to, żeby wszystkie osoby brały faktyczną odpowiedzialność za swoje działania i angażowały się w proces Data Governance. Niestety nie raz widzieliśmy sytuacje, gdy organizacja tryumfalnie rozdawała wśród swoich ludzi nowe role, z których nic potem nie wynikało – nikt nie rozumiał co ma robić, jakie są jego obowiązki i nie poczuwał się do odpowiedzialności za ich wykonywanie.
Czy przez data catalog można też zarządzać zdjęciami/dokumentami?
Tak, jest to możliwe. W takim przypadku konieczne jest przechowywanie zdjęcia / dokumenty w bazach semi-structured (bazy częściowo ustrukturyzowane), np. w postaci jsonów, w których sam dokument / zdjęcie byłoby jednym z atrybutów (referencja do pliku).