


Challenge
BlueSoft consultants faced the challenge of a huge data volume and unknown data quality distributed among multiple sources in an initially unknown manner (about 1.2 billion records to be processed in each project phase).
Knowledge about the source data shape and quality was limited. For business analysts to access raw data, several checks and metrics had to be built in the early beginning of the design and analysis process.
The data had to be processed in a safe and efficient manner with extensive monitoring and troubleshooting capabilities, as well as process orchestration and reporting at every stage of the project. Complex data processing mechanisms (ETL), non-trivial data matching (fuzzy matching), data cleansing and validation, manual data stewardship, error reporting, and processing automation were all needed as well.
Choosing the proper tool to address this complex task was one of the most important success factors.
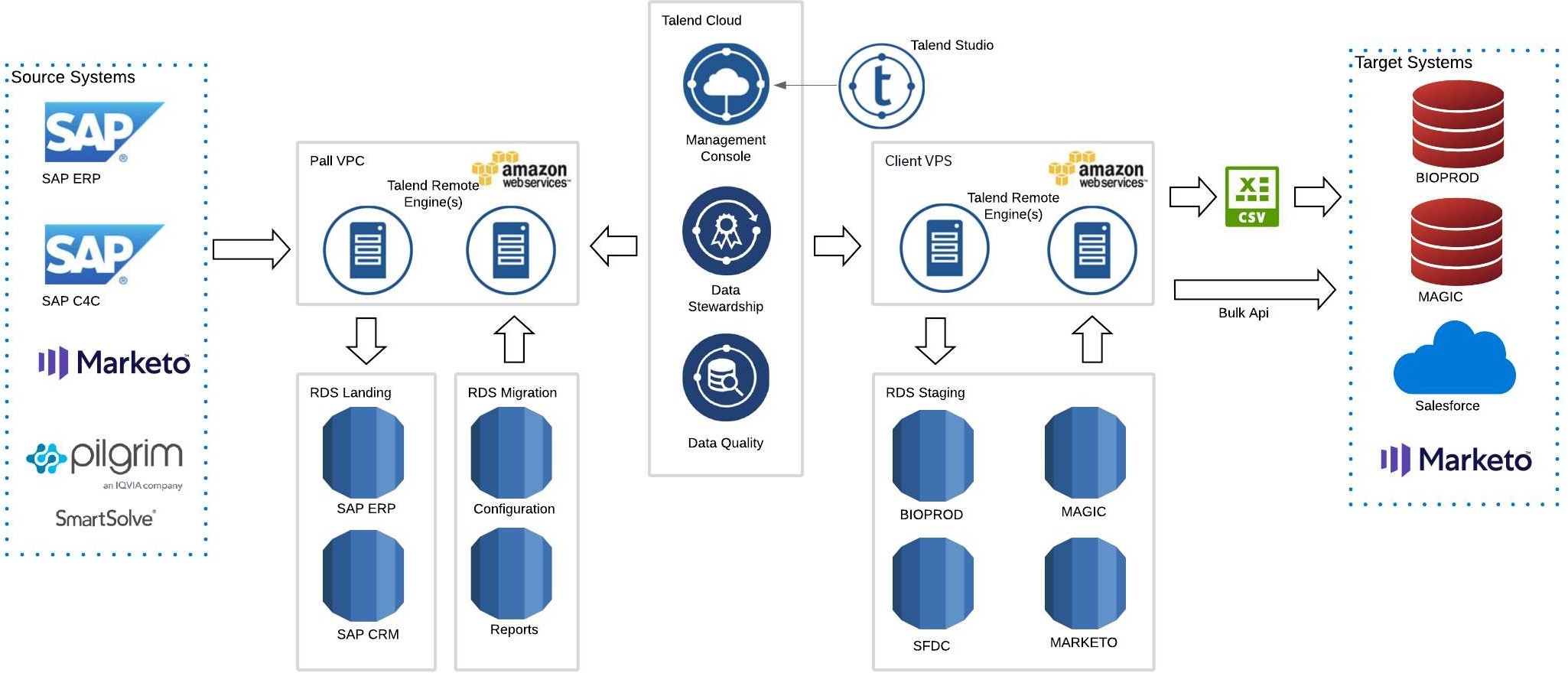
Solution
To meet those requirements, Talend products supported by AWS RDS were chosen as the main ETL tool after a series of POC sprints. High-level tech scope can be summarized with this graphic:

At first, BlueSoft team acquired core datasets from source systems and prepared a set of detailed data quality reports in order to support Company’s business analysts in deciding which data is eligible for migration and to be able to formulate detailed requirements.
The following challenges were addressed during the project’s lifetime.
Connectivity & throughput
Connectivity to multiple systems using different technical means has been established. The majority of the data from all the source systems had to be downloaded in order to make data analysis, verification, and potential cleansing possible. Every stage of the project required this operation to be repeated due to a variety of environments and data modifications. Billions of data records (TBytes) have been actively pulled from the sources multiple times and stored in RDS servers.
Data matching
In addition to quite common data transformations, which most modern tools can handle, we’ve extensively utilized data matching Talend components and a wide range of matching algorithms to achieve maximum data pairing and merging efficiency. In some case Talend Data Stewardship module came in handy as well.
Development process
In parallel to the general ETL process development and testing (multiple trial runs and test cycles), a wide range of error reports has been prepared in order to identify and bring attention to the most important data problems. The processed data was sensitive in nature, falling under GxP and personal data processing regulations, which is why in the majority of cases data fixing had to be addressed by business users in the source/target systems instead of the middleware. Technical data cleansing, such as encoding change, unwanted character removal, and data re-formatting took place on the fly. Production data was being pulled and dozens of error reports were recalculated and loaded into SharePoint on a weekly basis by Talend.
Thanks to the SaaS-based architecture of both Talend Cloud and AWS services, the migration team was able to seamlessly scale the solution avoiding bottlenecks, and improve efficiency, while narrowing migration execution time.
Platform scalling in the project

On top of scalability, which improves the performance and possibilities of the ETL process, significant pressure has been put on parallel processing. Both leveraging multiple Talend Remote Engines and multi-thread processing in Talend code itself added to the solution’s quality.
Moreover, the project team leveraged custom component creation capabilities to inject Python and Java code in order to optimize tasks executions even more.
The flexibility of database setup and replication on RDS combined with easy connectivity and job execution orchestration on Talend Cloud made data separation between environments straightforward. The main aim was to keep data tidy and independent through all the data migration testing and rehearsal phases.
Results
As a result of the two years of the project, a Talend-based solution was successfully implemented for this customer by a team including Bluesoft consultants and employees of merged companies. More than 6 TB of data have been migrated via AWS & Talend cloud, while more than 14 Talend knowledgeable and certified engineers worked on the migration and analysis of over a billion records database.
Once this project is finalized, the client plans to leverage Talend to:
- Improve data quality and perform data cleansing in core systems
- Automate manual processes concerning verification across systems
- Build several system integrations
- Perform next data migrations of different scale

6 TB
of cloud stored data at the moment
1.2 billion
records
10
Talend Remote Engines
2
years project

")



